Data lakes #
Modern businesses analyze and consume tremendous amounts of data, and modern data architecture has evolved to meet these business needs. Traditional data warehousing architectures struggle to keep up with the rate that businesses need to ingest and consume data.
A data lake is an architecture that allows your data to live in whatever format, software, or geographic region it currently resides in. This frees your data from vendor lock-in and removes the need for lengthy ETL processes that slow your business’s time-to-insight.
Architecture #
The modern data lake incorporates data transformation and governance in front of the lake, and is best described as a data lakehouse. The following diagram describes an example of data lakehouse architecture:
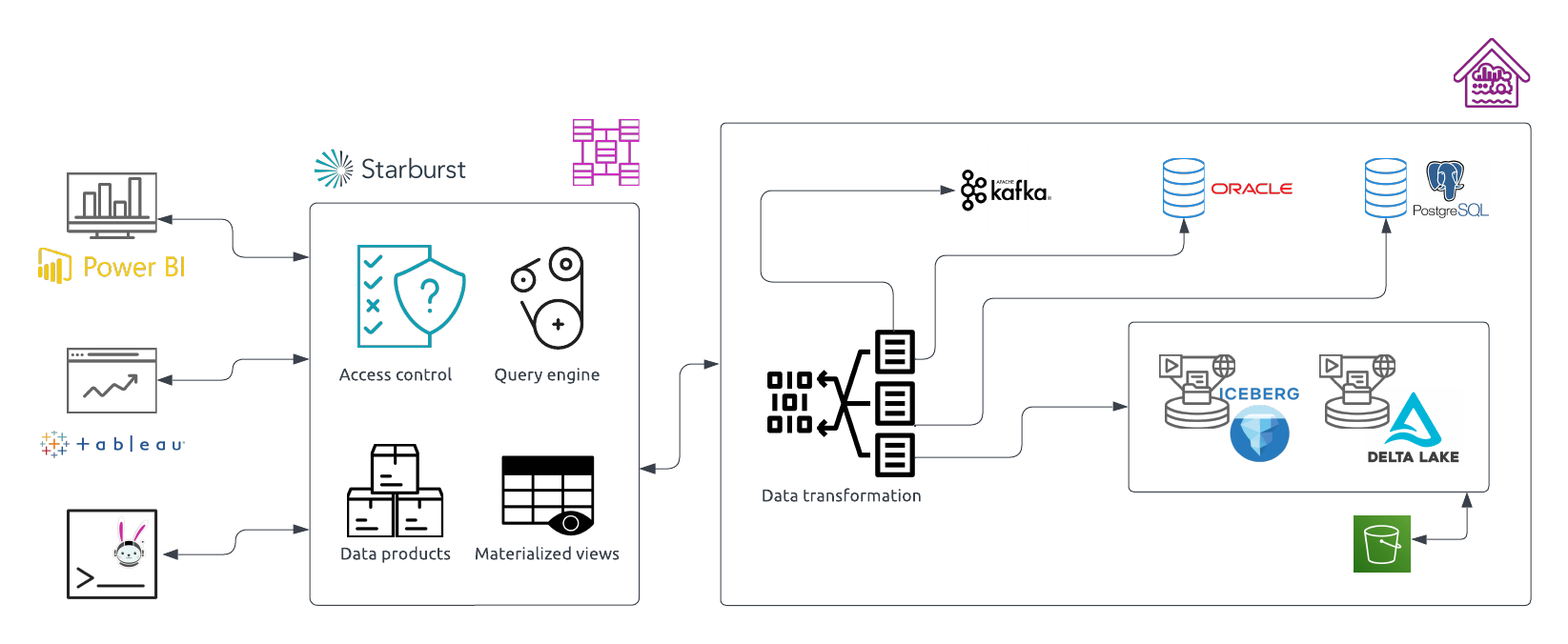
In this architecture, your data lives in whatever software, format, and location it needs in order to be most cost-effective on the lake. On top of this data storage layer, the lakehouse incorporates a data transformation layer that employs governance, materialized views, and other technologies and rules to ensure that the resulting data is ready for consumption.
The optimized data is then ready to be accessed by clients and BI tools through a query engine which handles data-level security, view management, and query optimization regardless of where in the lake the underlying data is stored.
Starburst for the data lake #
Starburst Galaxy and Starburst Enterprise platform (SEP) are ideal tools to get the most value out of your data lakehouse, with features to support scaling, optionality, high performance, and ease of data consumption.
Scaling and optionality #
Starburst products are designed to work in parallel with your data lakehouse, not lock your data into a restrictive, vendor-compliant architecture that increases costs and holds back your operational growth. Starburst products accomplish this with the following features:
- Flexibility to access a wide variety of data sources.
- Standard JDBC/ODBC drivers that allow connections to Starburst from many client and BI tools.
- Cloud-friendly cluster architecture that separates computational resources from storage, allowing for flexible growth in whatever way best suits your operational needs.
- Multi-cluster deployment options to handle cross-region workloads.
High performance #
Starburst products include a high-performing query engine out of the box, with the following features that support the most efficient use of your data lakehouse:
- Query planning that distributes workloads across cluster resources, and pushing optimizations down to data sources to improve both processing speeds and network utilization.
- Options to materialize data on the lake for high-speed access to data independent of performance on the data source.
- High-performance I/O with multiple parallel connections between Starburst cluster nodes and object storage.
- Object store caching and indexing to dynamically accelerate access to your lakehouse data.
Ease of consumption #
Starburst products are a central access point between your data consumers and your data lakehouse, streamlining access to the data most relevant to your users with the following features:
- Centralized access control role and attribute-based access control (RBAC/ABAC) systems per-product that dictate persona-based access to your data.
- Data product management that adds a semantic layer to your data for simplified consumption and sharing.
- Support for modern BI tools and clients, allowing for organization-wide sharing and utilization of data insights.
Is the information on this page helpful?
Yes
No