Galaxy cluster basics #
In Starburst Galaxy, a cluster provides the resources to run queries against numerous catalogs. You can access the data exposed by the catalogs with the query editor or other clients.
Access your account’s clusters from the navigaton menu by clicking Admin > Clusters.
Newly created Galaxy accounts typically have an example cluster with the name
sample for accounts created before August 30, 2023 or free-cluster for newer
accounts.
Starburst Galaxy lets you create, edit, delete, enable, and disable clusters, and lets you resume an auto-suspended cluster.
Concepts #
Creating and managing clusters is an essential task for a platform administrator in Starburst Galaxy. A cluster with the desired catalogs is required for a data consumer to use SQL statements in client tools to analyze the available data. The following important concepts for understanding how to perform this work efficiently.
Cluster maximums #
For all clusters, the maximum allowed query processing time in Starburst Galaxy is four hours. Longer running queries are terminated. Find relevant tips in query troubleshooting.
The number of clusters allowed per account is limited to 30 by default. Contact Starburst support if you need a higher limit.
To enable a cluster with more than 20 worker nodes, contact Starburst support.
Cloud provider region and catalogs #
Catalogs define the
connection details to access a data source. Any data source is located in a
specific cloud region of a specific cloud provider. For example, your Cloud SQL
for MySQL database is hosted in the us-east1 region of Google Cloud.
A cluster can include one or more catalogs. If multiple catalogs are configured, you can query them with SQL using the same client connection. You can also query the data in multiple catalogs within one SQL statement.
A cluster and all its configured catalogs are typically located in the same cloud provider and region. This allows for maximum performance and avoids data transfer costs for access across regions.
Size and scaling #
The size of a cluster determines the number of server nodes, including one coordinator and many workers, used to process queries. A larger cluster, consisting of more nodes, is capable of processing more complex queries, handling more concurrent users, and providing higher performance by using more resources.
You can create a cluster with any size, and change size based on the current needs. All nodes in a cluster are identical. Free clusters include a single node that acts as both the coordinator and worker. For paid clusters, set a fixed size or a minimum and maximum number of workers to scale between.
Best practice is to start with a smaller size cluster and determine whether the cluster is capable of processing all queries in your workload. Slow processing or out of memory failures typically suggest choosing a larger size.
Learn more about configuring autoscaling on a new or existing cluster.
If autoscaling is not sufficient to handle heavy workload demands on a cluster, you can create up to eight replicated clusters. When you create replicated clusters, Galaxy routes queries across the cluster and its replicas to distribute the workload. Replicated clusters are essentially a form of horizontal scaling, while autoscaling is a form of vertical scaling. You cannot use replicated clusters and autoscaling at the same time. For more information, see deployment set routing.
Cluster status and transitions #
A cluster can be in one of the following states:
- Not enabled
- A cluster that is not enabled consists of a small configuration set only. No significant resources are used, and no costs are incurred.
- Starting
- A cluster currently entering the running state.
- Running
- A running cluster consists of a number of server nodes. It continues to be in the running state, while users are submitting queries for processing.
- Suspended
- A suspended cluster consists of a small configuration set, and a mechanism to listen to incoming user request. It does not include any actively running server nodes, and no costs are incurred.
Configuration changes to Galaxy catalogs or clusters are implemented as follows:
- For suspended or disabled clusters, configuration changes are implemented immediately.
- For running clusters, most configuration changes are saved and are implemented when you run the next query.
- For some cluster conditions, after you make configuration changes, Galaxy may show a dialog asking you to manually stop and restart the cluster.
A newly created cluster begins un-enabled, and can be enabled in the cluster list.
A running cluster can be manually disabled in the cluster list.
Uptime #
A running cluster becomes idle when no queries are submitted and all processing of queries is completed. Idle clusters automatically transition to suspended status when the configured auto-suspend time is reached.
Available auto-suspend times include 1 minute, 5 minutes, 15
minutes, 30 minutes, and 1 hour.
For free clusters, the options are limited to 1 minute and 5 minutes.
When a user submits a query to a suspended cluster, the cluster is started, and the query is processed. The user must wait for the cluster to start, which typically takes between one and five minutes.
You can also configure a cluster to Never suspend. This causes the cluster to remain up and running, even if no queries are processed and the cluster is idling. The advantage of this behavior is that any issued query can be processed immediately, as there is no wait time until the cluster started. The disadvantage is the increased cost incurred for continuously running a cluster. The Never suspend option is not available for free clusters. By default, an accelerated cluster is configured to Never suspend because restarting a suspended cluster requires warming up the cache again and recreating indexes.

Use cluster scheduling to transition clusters between running and suspended status automatically, based on specified days and times.
Execution mode #
When configuring your cluster, choose between Standard, Fault tolerant, and Accelerated listed in the Execution mode drop-down menu.
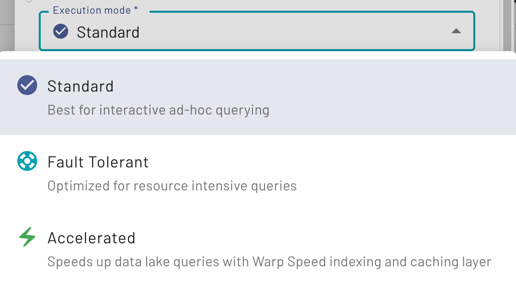
Learn more about the three different execution modes that Starburst Galaxy has to offer.
Free cluster size.Query result caching #
For all cluster sizes except Free, you can optionally set the cluster to cache
query results for a specified period of time. For more information, see Query
result caching.
Is the information on this page helpful?
Yes
No