Amazon S3 catalog #
This page describes connecting to general Amazon S3 object storage.
If you want to connect to an Amazon S3 Table, see Amazon S3 Tables.
Use an Amazon S3 catalog to configure access to Amazon S3 object storage hosted on Amazon Web Services.
The data can be stored using Iceberg, Delta Lake, Hive, or Hudi table formats.
Starburst Galaxy connects to Amazon S3 via VPC endpoints over an encrypted connection.
Metadata about the objects and related type mapping must be stored in a metastore. You can use Amazon Glue, a Hive Metastore Service, or the built-in metastore.
Follow these steps to create a catalog for S3:
- In the navigation menu, select Data, then Catalogs.
- Click Create catalog.
- On the Create a catalog pane, click the S3 icon.

- Configure the catalog as prompted in the dialog.
- Test the connection.
- Connect the catalog.
- Set any required permissions.
- Add the new catalog to a cluster.
The following sections provide more detail for creating S3 catalog connections.
Define catalog name and description #
The Catalog name is visible in the query editor and other clients. It is used to identify the catalog when writing SQL or showing the catalog and its nested schemas and tables in client applications.
The name is displayed in the query editor, and in the output of a SHOW
CATALOGS command.
It is used to fully qualify the name of any table in SQL queries following the
catalogname.schemaname.tablename syntax. For example, you can run the
following query in the sample cluster without first setting the catalog or
schema context: SELECT * FROM tpch.sf1.nation;.
The Description is a short, optional paragraph that provides further details about the catalog. It appears in the Starburst Galaxy user interface and can help other users determine what data can be accessed with the catalog.

Authentication to S3 #
Select between Cross account IAM role or AWS access key to grant access to the object storage.
With Cross account IAM role, provide an alias for the role in Starburst Galaxy and the AWS IAM ARN.
With AWS access key, provide the AWS access key for S3 and the AWS secret key for S3.
Read External security in AWS to learn about configuring these details in the AWS console.
Metastore configuration #
Before you can query data in an object storage account, it is necessary to have a metastore service associated with that object storage.
For more information about object storage and the requirement for a metastore, see Using object storage systems.
Starburst Galaxy metastore #
Starburst Galaxy provides its own metastore service for your convenience. You do not need to configure and manage a separate Hive Metastore Service deployment or equivalent system.
In Metastore configuration, select Starburst Galaxy to set up and use the built-in metastore provided by Galaxy.
For Amazon S3 and Google Cloud Storage, create a bucket in your object storage account, and create a directory in that bucket. Provide that bucket name and directory name. This location is then used to store the metastore data associated with this S3 or GCS account.
For Azure ADLS, create a container in your storage account, and create a directory in that container. Provide this storage container name and directory name. This sets up the location used to store the metadata associated with this storage account.
The meanings of the two Allow controls are the same for a Starburst Galaxy metastore as for a separate Hive Metastore Service, described previously.
Note that deletion of the catalog also results in removal of the associated Starburst Galaxy metastore data.
AWS Glue #
You can use AWS Glue to manage the metadata about your object storage. Configure access to AWS Glue with the following parameters:
- AWS Glue region
- Access security with AWS access key for Glue and AWS secret key for Glue or Cross account IAM role
Read External security in AWS to learn about configuring these details in AWS.
Hive Metastore Service #
You can use a Hive Metastore Service (HMS) to manage the metadata for your object storage. The HMS must be located in the same cloud provider and region as the object storage itself.
A connection to the HMS can be established directly, if the Starburst Galaxy IP range/CIDR is allowed to connect.
If the HMS is only accessible inside the virtual private cloud (VPC) of the cloud provider, you can use an SSH tunnel with a bastion host in the VPC.
In both cases, configure access with the following parameters:
- Hive Metastore host: the fully qualified domain name of the HMS server.
- Hive Metastore port: the port used by the HMS, typically 9083.
- Allow creating external tables: switch to indicate whether new tables can be created in the object storage and HMS from Starburst Galaxy with CREATE TABLE or CREATE TABLE AS commands.
- Allow writing to external tables: switch to indicate whether data management write operations are permitted.
Unity catalog metastore #
Previously, you could specify the Databricks Unity Catalog as a metastore here to manage the metadata for your object storage. Unity Catalog is now configurable as a standalone catalog in the Catalogs pane.
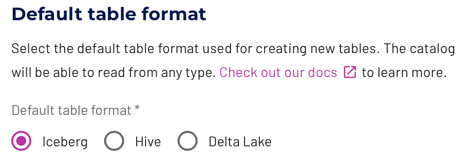
Default table format #
Starburst Galaxy provides a simple way to specify the default table format for an object storage catalog. This applies to newly created tables, and does not convert any existing tables. The following table formats are supported:
- Iceberg
- Delta Lake
- Hive
- Hudi
If you are unsure which format to use, we recommend leaving the default
Iceberg format selected. More information is available in the discussion of
the format options on the
Storage
page.
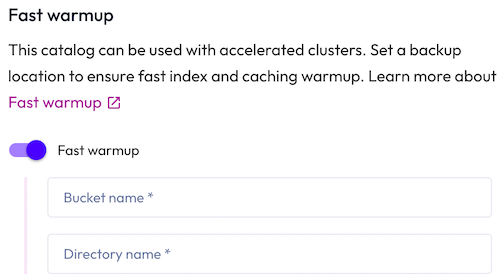
Fast warmup #
If you intend to connect the catalog to an accelerated cluster, Starburst Warp Speed optionally provides fast warmup.
To set a backup location in your object storage for index and data caches, enter a Bucket name and a Directory name within the bucket where the cache data is to be stored.
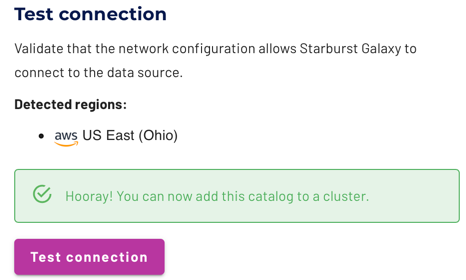
Test the connection #
Once you have configured the connection details, click Test connection to confirm data access is working. If the test is successful, you can then save the catalog.
If the test fails, look over your entries in the configuration fields, correct any errors, and try again. If the test continues to fail, Galaxy provides diagnostic information that you can use to fix the data source configuration in the cloud provider system.
Connect catalog #
Click Connect catalog, and proceed to set permissions where you can grant access to certain roles.
Set permissions #
This optional step allows you to configure read-only access or full read and write access to the catalog.
Use the following steps to assign read-only access to all roles:
- Select the Read-only catalog switch to grant a set of roles read-only access to the catalog’s schemas, tables, and views.
- Next, use the drop-down menu in the Role-level permissions section to specify the roles that have read-only access.
- Click Save access controls.
You can specify read-only access and read-write access separately for different sets of roles. That is, one set of roles can get full read and write access to all schemas, tables, and views in the catalog, while another set of roles gets read-only access.
Use the following steps to assign read/write access to some or all roles:
- Leave the Read-only catalog switch cleared.
- In the Role-level permissions section:
- Expand the drop-down menu in the Roles with read and write access field and select one or more roles to grant read and write access to.
- Expand the drop-down menu in the Roles with read access field and select one or more roles from the list to grant read-only access to.
- Click Save access controls.

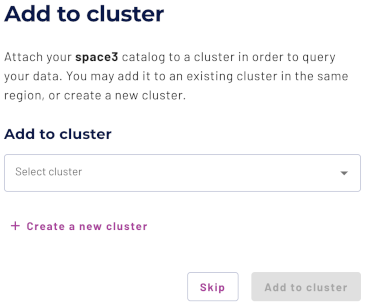
Add to cluster #
You can add your catalog to a cluster later by editing a cluster. Click Skip to proceed to the catalogs page.
Use the following steps to add your catalog to an existing cluster or create a new cluster in the same cloud region:
- In the Add to cluster section, expand the menu in the Select cluster field.
- Select one or more existing clusters from the drop down menu.
- Click Create a new cluster to create a new cluster in the same region, and add it to the cluster selection menu.
-
Click Add to cluster to view your new catalog’s configuration.
Now that your object storage catalog has been added to a cluster, you can run queries against Iceberg, Delta, Hive, and Hudi table formats using Great Lakes connectivity.
SQL support #
SQL statement support for your object storage catalog depends on the table format in use. Details are available on the storage and table formats pages.
Is the information on this page helpful?
Yes
No